
Vorfälle systematisch erkennen, effektiv beheben und strukturiert analysieren
Moderne Softwaresysteme und IT-Infrastrukturen sind komplex, und Komplexität geht zwangsläufig mit Überraschungen einher. Um dem vorzubeugen und (im Fall der Fälle) die Auswirkungen zu minimieren, ziehen Teams zwar ausgefeilte und redundante Sicherheitsmechanismen ein, doch im Hinblick auf IT-Systeme bedeutet Komplexität, dass Störungen und Ausfälle keine Frage des „Ob“, sondern des „Wann“ und „wie lange“ sind.
Dafür gibt es zahlreiche denkbare Ursachen: Hardware-Defekte, schlechten Code, fehlerhafte Konfigurationen, Angriffe und vieles mehr. Und der Ausfall eines IT-Systems ist immer kostspielig. Bei öffentlichen Instanzen können Kunden und User den Dienst nicht nutzen. Die Downtime eines internen Systems führt wiederum zu Produktivitätsverlusten und Arbeit, die zwangsweise liegen bleibt.
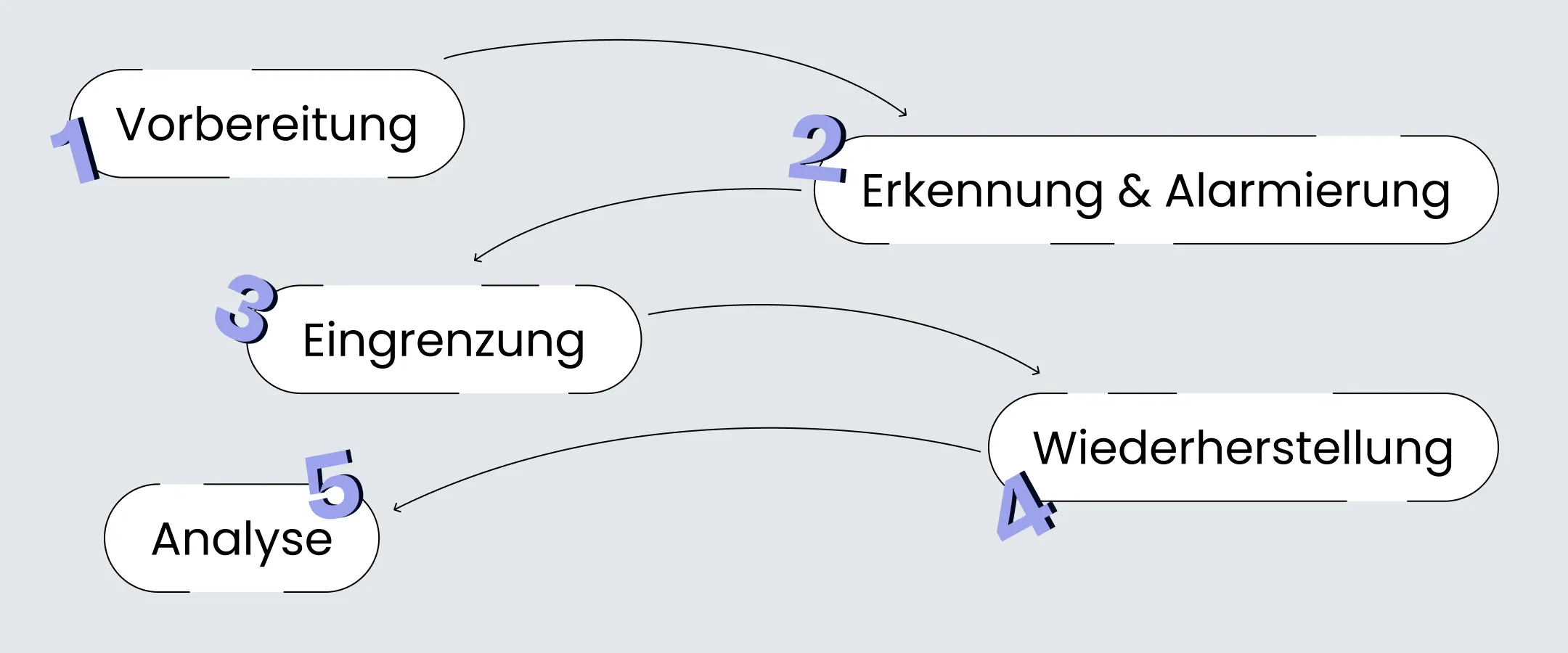
Sicherzustellen, dass Störungen schnell erkannt, effektiv behoben und sinnvoll nachbereitet werden, fällt in den Bereich des IT-Service-Managements (ITSM). Deshalb erfordert ITSM ein modernes Incident-Management, das idealerweise einen Zyklus aus fünf Stadien umfasst: Vorbereitung, Erkennung und Alarmierung, Eingrenzung, Wiederherstellung, Analyse.
Organisationen, die Teile des vollständigen Incident-Management-Zyklus’ vernachlässigen, gehen unnötige Risiken ein. Sie laufen Gefahr, dass Teams auf Störungen falsch reagieren, was Vorfälle in die Länge ziehen und höhere Kosten verursachen kann.
Wir wollen die fünf Stadien des Incident-Managements einmal näher beleuchten.
Incident-Management-Phase 1: Vorbereitung
Die Vorbereitung ist ein essenzieller und dennoch oft stiefmütterlich behandelter Teil des Incident-Managements. Tatsächlich beschäftigen sich manche Teams erst dann mit Fragen der Vorbereitung, nachdem ein Vorfall sie unvorbereitet getroffen und Chaos angerichtet hat.
Erfahrene ITSM-Teams nehmen die Vorbereitung ernst. Sie erkunden Was-wäre-wenn-Szenarien und definieren Prozesse dafür. Sie packen sozusagen einen stets zugriffsbereiten Rettungsrucksack mit kritischen Informationen, die im Problemfall ohne Verzögerungen griffbereit sein müssen.
Durch die Zentralisierung dieser Daten spart das Team im Zweifel viel Zeit ein, da sie nicht erst zusammengetragen werden müssen. Dazu können je nach Teamstruktur und eingesetzten Systemen Incident-Response-Pläne, Kontaktlisten, Bereitschaftspläne, Eskalationsrichtlinien, Linklisten zu wichtigen Kommunikationswerkzeugen, Zugangscodes, Compliance-Vorschriften, technische Dokus und Handbücher gehören.
Incident-Management-Phase 2: Erkennung und Alarmierung
Tritt ein Vorfall auf, sollte ein Team ihn erkennen, bevor massenhaft Tickets aus dem Kundenportal quellen und die Servicetelefone heißlaufen. Eine wichtige Frage lautet dabei, auf welche Weise das Team alarmiert wird.
Mittlerweile gibt es eine Vielzahl hochwertiger IT-Monitoringwerkzeuge, die das Team über Anormalitäten und Vorfälle informieren. Doch viele Tools bedeuten im Zweifel auch viele Alarme oder gar False Positives, die den Reaktionsprozess beeinträchtigen. Deshalb ist es sinnvoll, in das Monitoring eine zusätzliche Schicht einzubauen, die den Alarmierungsprozess zentralisiert.
Moderne Incident-Management-Tools wie Opsgenie von Atlassian ermöglichen es, den Prozess deutlich zu straffen. Sie bieten automatisierte Alarmierungs-Workflows, die auf Alarmtypen, Teamplänen und Eskalationsrichtlinien basieren, sodass sich menschliche Fehler und/oder Verzögerungen weitgehend ausschließen lassen.
Außerdem kann es – insbesondere auf großer Skala – sinnvoll sein, das Monitoring an sich zu überwachen, denn auch die Monitoring-Tools sind nicht immun gegen Vorfälle. Ein holistischer Alarmierungsprozess sorgt dafür, dass sowohl die Systeme als auch die Überwachungswerkzeuge kontinuierlich überprüft werden.
Incident-Management-Phase 3: Eingrenzung
Die Triage im Incident-Management ist vergleichbar mit der im medizinischen Bereich: Im ersten Schritt geht es darum, das Ausmaß des Vorfalls zu identifizieren. Dann müssen alle Vorfälle eingegrenzt und möglichst separiert werden, um zu verhindern, dass die Situation sich weiter verschlimmert. Alle Aktivitäten in dieser Phase drehen sich darum, den Schaden zu begrenzen und weitere Auswirkungen zu vermeiden.
Der Fokus liegt hier auf temporären Lösungen, beispielsweise der Isolation eines Netzwerks, dem Zurücksetzen eines Builds, dem Neustart der Server. Im Idealfall ist das Problem damit gelöst, doch das Minimalziel besteht zunächst darin, den Umfang des Vorfalls zu begrenzen. Alle weiteren Schritte und Maßnahmen, also die Bemühungen zur vollumfänglichen Wiederherstellung, folgen später.
Möglichst parallel sollte eine offene Kommunikation gegenüber den Kunden stattfinden. Das ist mitten in der Hitze eines IT-Crashs natürlich leichter gesagt als getan. Doch gerade im Problemfall ist Transparenz im Umgang mit den Kunden ein hohes Gut, das Vertrauen schafft. Deshalb ist es sinnvoll, neben dem Notfallrucksack einen Kommunikationsplan bereitzuhalten.
Statuspage, Twitter und Nutzerforen sind geeignete Plattformen, um entsprechende Informationen zu teilen. Diese offene Kommunikation sollte das Team auch in den nachfolgenden Incident-Management-Phasen beibehalten.
Incident-Management-Phase 4: Wiederherstellung
In diesem Stadium implementiert das Team langfristige Lösungen, die gewährleisten, dass der Vorfall vollumfänglich und effektiv gelöst ist. Es geht darum zu verstehen, welche Ursachen zu den Problemen geführt haben und wie die Voraussetzungen so korrigiert werden können, dass ähnliche Vorfälle in Zukunft auszuschließen sind.
Das Ziel dieser Phase ist nicht, das System wieder in den ursprünglichen stabilen Zustand zu versetzen, sondern es noch besser und sicherer zu machen. Es sollte dieselben operativen Fähigkeiten besitzen, aber zusätzlich Schutz gegen ähnlich gelagerte Vorfälle bieten.
Incident-Management-Phase 5: Analyse
Die Workflows im professionellen Incident-Management enden nicht, wenn der Staub sich gelegt hat und das System wieder reibungslos und sicher läuft. Nun beginnt die wichtige Phase der Analyse. Ein solches “Postmortem” hat den Zweck, sowohl die systemischen Ursachen des Vorfalls zu klären als auch die einzelnen Schritte bei der Behebung kritisch zu beleuchten.
Auf dieser Grundlage identifiziert das Incident-Team Verbesserungsmöglichkeiten im Hinblick auf die Systeme und Prozesse. Die Evaluation dieser Informationen hilft bei der Entwicklung neuer Workflows, die eine höhere System-Resilienz und schnellere Reaktionen auf Vorfälle unterstützen.
Eine gute Postmortem-Analyse betrachtet den gesamten Vorfall und beantwortet die Fragen nach dem Wer, Was, Warum und Wie – allerdings ohne einzelne Kolleg*innen persönlich zu beschuldigen und in Haftung zu nehmen: IT ist immer ein Teamsport! Im Kern dreht sich die Analyse darum, aus dem Vorfall zu lernen, um die Performance des Teams zu optimieren und Referenzmaterial für künftige Vorfallsszenarien zusammenzustellen.
Erfahrene ITSM-Teams erstellen nach jeder Störung Postmortem-Analysen – nicht nur nach großen Ausfällen. So vermeiden sie die Gefahr, nachklingende Effekte kleinerer Vorfälle womöglich zu übersehen. Ein detaillierter Bericht ist wahrscheinlich nicht für jeden einzelnen Vorfall nötig, doch für ein kompaktes Review sollte immer Zeit sein. Das Bewusstsein für bestimmte Situationen fördert die Weiterentwicklung des gemeinschaftlichen Wissens und eine Kultur der kontinuierlichen Verbesserung.
Veränderung ist Normalität
In modernen IT-Umgebungen ist Veränderung die einzige Konstante. Das bedeutet, dass Systeme und Infrastrukturen permanent durch neue Faktoren unter Stress gesetzt werden. Wie eingangs erwähnt, ist es lediglich eine Frage der Zeit, bis ein beliebiges System eine Störung aufweist.
Erfahrenen Teams ist dieses Bewusstsein in die DNA übergegangen. Sie sind gründlich auf Vorfälle vorbereitet und haben jederzeit Zugriff auf wichtige Tools und Informationen, die sie dabei unterstützen, Probleme schnell und effektiv einzugrenzen, zu beheben und zu kommunizieren.
Bereit für modernes ITSM? Hier sind Ressourcen!
Jede Organisation, die auf IT-Service-Management setzt, fordert eine neue Denk- und Arbeitsweise von ihren Teams. Entwicklung, Betrieb und Support sind nicht mehr klar voneinander getrennt, sondern gehen Hand in Hand.
Du möchtest tiefer in die Welt von ITSM einsteigen? Dann haben wir noch mehr Lesestoff für dich: Lade dir einfach unser kostenloses Whitepaper „Wie funktioniert IT-Servicemanagement?“ herunter!